Головач про классификации
Вот и Влад Головач разродился на тему классификаций. Все правильно написал. И ссылки дал хорошие.
N-мерная связь
Лучше вот так: любые N кейвордов могут находиться в любом N-местном отношении друг с другом! Вот теперь — полноценная система. (тут)
Илья Бирман в своем желании хитро меня подколоть случайно оказался прав. Это действительно полноценная система, при этом довольно удобная. Но есть нюанс — использовать это нужно уже не по отношению к ключевым словам, а по потношению к записям.
Любые N записей могут находиться в любом N-местном отношении друг с другом.
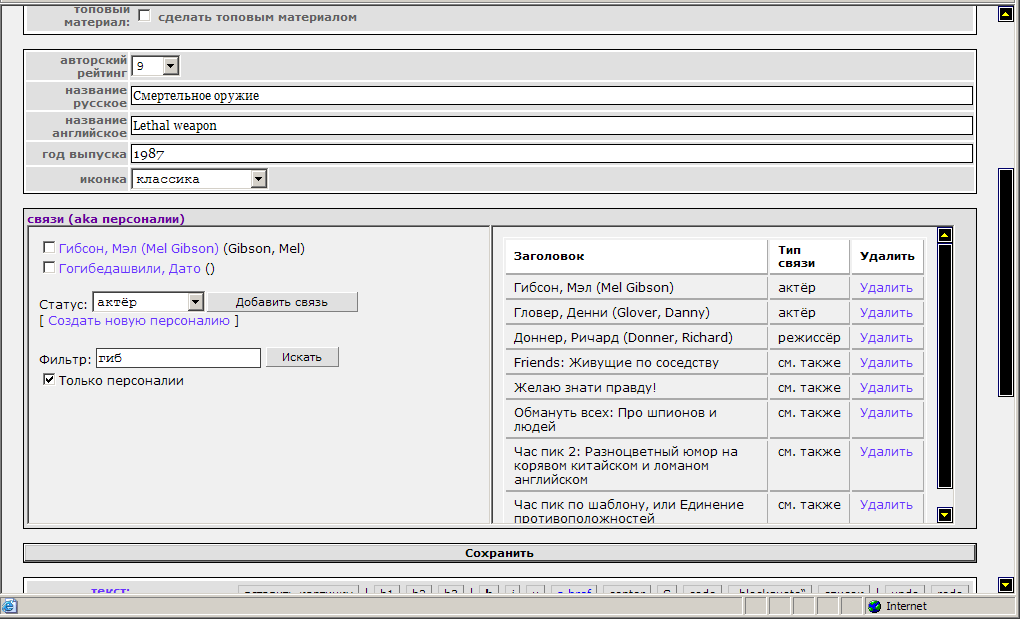
Реализовано это было мной уже более года назад и оправдало себя. Вот, например, скриншот со сквадрона, где мы видим, что у документа «Смертельное оружие» документ «Мел Гибсон» является «актером», а фильм «Час Пик» соотносится связью «смотрите также».
{kind=link}
ToDo: content is a whore
ToDo: написать книгу «Сontent is a whore» и через 20 лет стать культовым писателем.
(Интеллектуальный юмор, не всем понятен).
Knowledge base
Не так давно мы с вами — а верней я — рассуждал о блогах и пришел к неутешительному выводу, что бытие определяет сознание, the medium is the message, а блог — «это та ерунда, которая получилась после массовой реализации возможности быстрой и легкой публикации заметок на „домашних страничках“».
Блог — всего лишь одна из форм организации контента, просто форма не особо удачная, да и контент подходящий — сиюминутные ремарки о-чем-вижу-о-том-и-пою, иными словами — «чем удобряли, то и выросло».
Есть и другие жанры. Про один из таких жанров — назову его условно knowledge base — и я хочу немного поговорить.
Рано или поздно, создавая контент, который востребован и не теряет актуальности со временем (или теряет, но не так быстро, как, например, новости), мы начинаем понимать две простые вещи:
1. В тематике контента обнаруживаются закономерности и между разными документами можно провести некие семантические связи. Как это будет реализовано — ключевые слова, категории, рубрики, «смотрите также», хитроумные костыли для ЖЖ — не важно.
2. Так как материал устаревает медленно, время написания и вообще сортировка по времени написания по большому счету теряет смысл.
Переписав текст про ЧПУ, который оставался актуальным четыре года(!), и сделаев его совсем up-to-date, а так же написав текст о том, что же такое блог и использовав при этом наброски из «Регистра», я придумал вот что:
Документы в Сети не обязаны быть статичными. Но даже динамичный блог — это куча статичных заметочек, а когда нам нужно развить тему, мы просто пишем еще одну заметку. Иногда это оправдано, иногда — нет. Но почему-то все всегда (или почти всегда) забывают о том, что текст-то — электронный, поэтому его можно просто дописать или переписать.
Влад Головач предлагает всячески чистить архивы блога, удаляя ненужную и устаревшую информацию. Но — тогда это уже будет не блог, и вообще Влад говорит, что «хитрость в том, чтобы изменить магистральное направление блога в прошлое (которого как минимум больше)». Совершенно верно. Но есть нюанс.
Знаете, почему когда нужно продолжить тему в блоге, то об этом пишется новая заметка (в которой пусть даже и ставятся ссылки или ключевые слова, линкующие ее с предыдущими по теме)? Да потому, что новая заметка всегда сверху.
А сверху она потому, что она новая.
Но нам ничего не мешает сделать такой сайт, на котором мы будем развивать круг тем не только добавляя новые документы и связывая их со старыми, но и редактируя старые, при этом сортируя документы не по дате написания, а по дате обновления.
Выглядит это так: есть рубрикация по темам. В каждой теме есть три блока документов:
Первый — основополагающий/темообразующий документ/документы. Основной документ, раскрывающий тему и постоянно обновляющийся.
Второй — исходный материал, тот сор, из которого вырастает темообразующий блок документов.
Например, темообразующий документ: /entry/2196
Исходный/черновой материал: http://nudnik.ru/keys/blogs
Третий — устаревшие/архивные материалы, в том числе и предыдущие версии темообразующих документов.
Пользователю же при первом знакомстве всегда подсовывается темообразующий блок. Например, если я пишу в блоге заметку — ну, скажем, «еще один способ сделать ЧПУ», — то человек, который не знает, что это такое, вынужден идти по ключевым словам и узнавать.
Если же делать knowledge base, то пользователь видит, что обновилась/завелась тема ЧПУ и когда он в нее заходит, то ему не вываливается «а вот все, что у меня есть про ЧПУ, разбирайся и сортируй сам».
Кстати, когда я писал диплом, у меня была бредовая идея сделать его в виде гипертекста, основной корпус диплома сделать в виде, скажем, пятистраничного текста, который кратко, но по существу передает все содержание диплома, и в котором в ключевых местах понатыканы ссылки [show me more]. Грубо говоря, человек, который читал бы диплом, смог бы углубиться в него в любом месте и на любой уровень.
Представьте, если бы каждый абзац можно было бы расширить на страницу, а в свою очередь каждый абзац там — еще на страницу.
Вот, примерно так. Самое смешное, что это придумано сто лет назад и называется гипертекстом. Проблема в том, что почти все реализации гипертекста выходили не очень-то удачными, да и создавать полноценный гипертекст гораздо сложнее, чем простой текст.
Еще я хотел что-то хорошее написать про Wako Wiki, ибо это – инструмент, заточенный помимо всего прочего и на редактирование документов, а не на добавление новых (как блог). Проблема с Wiki только одна – на мой взгляд – там все – как бы сказать – кишками наружу, что ли. То есть, система ориентирована на писателя или на коллектив писателей, — что идеально подходит для совместного творчества, организации совместной работы над документами или для индивидуальный вещей, — таких как ToDo, например, но не очень-то ориентирована на простого читателя, которому очень много вещей просто не надо видеть.
Вот, пожалуй и все.