Тэги 2.0: сontribute or not!
В последнее время я работаю в Яндексе. Это такая интернет-компания, поэтому я время от времени думаю про всякие интернетовские вещи, типа вики, голосований или прочего.
Некоторые из этих мыслей не дают Яндексу неоспоримое конкурентное преимущество, поэтому не подпадают по NDA, но делают мир лучше, поэтому грех не поделиться. Особенно учитывая то, что на самом-то деле я не почетный член Yandex Labs и занимаюсь совсем другим.
Сегодня я долго и нудно думаю про тэги, ярлыки, категории, ключевые слова, — про эти штуки, которые пользователи добавляют к своим документам непонятно зачем и непонятно как.
Речь пойдет о тэгах на массовых сервисах.
Костя Коломеец придумал себе замечательный принцип — «сontribute or GTFO» и теперь носится с ним. Более емкую и понятную формулировку того же самого я видел у кого-то на сайте в виде disclaimer’а «Если ты нехороший человек, иди нахуй отсюда!».
Костя мечтатель, а принцип работает только в маленьких сплоченных группах («сектах»).
В реальности все не так. Все из вас наверняка видели онлайновые игрушки, типа «некое место, где все и каждый может составлять слова из букв». Этого зрелища хватает минут на пять, основные паттерны поведения понятны сразу. Даже если не брать случаи явного вандализма, коллективная работа и сontribute не выходит не только потому, что люди к ней не способны, но еще и потому, что способа договориться у них нет.
Тэги — наиболее уродское изобретение вебдваноля. Ровно по тем же причинам: предполагается, что люди «как масса» обладают неким интеллектом и способны действовать сообща.
Наглядный пример, почему весь этот вебдваноль не работает. Не глядя могу сказать, что одним из самых популярных тегов на яндекс.фотках будет тэг «я».Как легко догадаться, там должен быть изображен я. Но там почему-то изображен вовсе не я, а какой-то хуй в панамке.
(Смех в зале).
И если вдуматься, это не шутка.
Язык многозначен, уровень владения им у всех разный, все думают по-разному, а кто-то вообще не думает; правил заполнения тэгов нет никаких.
На выходе получается вполне наглядная картина: некий срез понимания того, как тэги нужно заполнять, помноженный на популярные темы и закрепленный в виде облака тэгов.
В этом, кстати, сакральная суть вебдваноля: взять много-много говна и снимать с него сливки. Все, что снизу, уже не найдет никто. Понятно, что тэг «кошки» на каком-нибудь фотохостинге будет мегапопулярен до такой степени, что «кошечками», «котятами» и «котами» можно вроде как и пренебречь.
На фотки.яндексе запрос «кошки минус коты» дает 88 тысяч фотографий, «коты минус кошки» — 18 тысяч. И пять тысяч «котят». Еще есть «cats» и «кошечки». Это всё одно и то же, но в Облаке Тэгов пользователю предлагают только «кошек». Процентов 30 теряется, но UGC — такая помойка, что все к подобному поведению привыкли.
Кто смог, тот всплыл, ага. При этом хорошо, что Яндекс ищет по тэгам с учетом форм слова, то есть «кошки» и «кошка» — это одно и то же. В других местах это совсем не так.
Но это детские примеры. Желающие могут угадать, какой тэг приписал автор своему посту «КАК ВЫТАСЧИТЬ КЛЕЩА».
Конечно же, «ПАРАЗИТЫ КЛЕЩ». Это один тэг.
Первые три мысли, которые возникают сразу:
1. Синонимы.
2. Поиск.
3. Конечно же, «паразиты / клещ».
Тэги против категорий.
Начнем с конца, «паразиты / клещ». Давно, до тэгов, были попытки создать всеобъемлющую классификацию зверей, птиц, гадов морских и всего, что есть в этом мире. Да, я говорю о древовидной классификации. Проблемы с ней были ровно те же: сотням людей приходилось понимать логику одного, который поместил, скажем, «компьютерные игры» в «компьютер / софт / игры», а не в «развлечения / игры / компьютерные».
Cовершенно очевидно, что игры должны быть и там и там, при этом это должны быть «одни и те же игры».
Продолжая мысль — те же «игры» могут быть и корнем (главной категорией) в одном случае, и подкатегорией — в другом. Очевидно, что нужна не древовидная структура, а скорей структура связей между категориями. Для умных — граф категорий с выделением корневых узлов. Очевидно, что категории должны отражать интересы пользователей, как тэги. Не на уровне «популярные категории выводятся жирным шрифтом», а на уровне «есть интерес — есть категория».
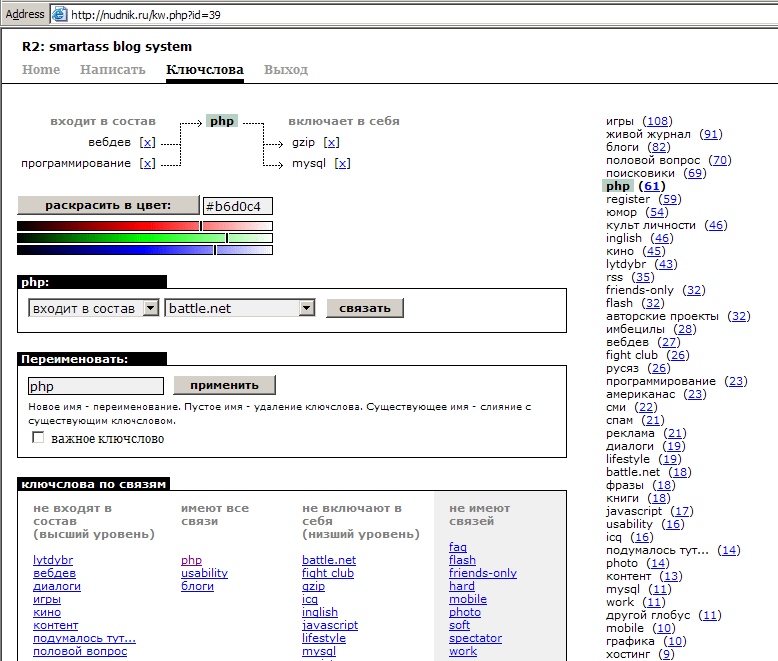
Что-то похожее сделано у меня на nudnik.ru: тэги+связи, важные тэги, аналог «корневой категории», выделяются руками.
Важный нюанс: эта система связывает уже существующие тэги, всеобъемлющую классификацию она создать не пытается.
Идеальная система тэгов на любом посещаемом сайте должна выглядеть так:
1. Пользователи вводят тэги в обычном порядке.
2. Модераторы берут существующие тэги и выстраивают между ними связи. Да-да, модераторы. Если вы считаете, что можно создать сайт с UGC без модераторов, то закройте эту страницу и всё забудьте.
При этом эта задача «модерации» тэгов гораздо более продуктивна, чем модерирование постов: новые тэги появляются не так часто, достаточно из связать один раз, и это будет работать надолго.
2.5. Одна из таких связей — несомненно, связь типа «синонимы». Достаточно один раз завязать всех «кошек» на одной слово — и всё, проблема с котами решена once and for all. При этом у синонимов должен быть один главный, вокруг которого растет гнездо. (Бесполезный факт: синонимы растут в гнездах).
Когда пользователь вводит неглавный синоним, этот синоним должен автоматически заменяться на главный. Да, это будет фрустировать пользователя, но окончательно решит проблему с двояким толкованием термина «киски».
3. После редактирования связей происходит автоматическая чистка тэгов в существующих «постах». Например, «cats, киски, кошки, животные» становятся просто «кошками». «Животные» убираются по понятным соображениям: «кошки / животные», то есть «кошки» входят в «животных», и при выборке по тэгу «животные» кошки будут показаны тоже.
Один из плюсов тэгов — в том, что одной записи можно поставить более одного тэга. Но этот функционал чаще приводит к «стрельбе наугад», когда пользователь пытается предугадать, какой синоним «кошек» все-таки нужно использовать, и в результате пишет их все, — и заодно придумывает новые.
После чистки же (в идеале) остаются только несвязанные между собой тэги, например, пост про ребенка и кошку будет иметь тэги, натурально, «ребенок» и «кошка».
4. Пользователю предлагается новый улучшенный интерфейс ввода тэгов, с автозаполнением, подсказками, блэкджеком и шлюхами.
Наиболее близка с идеалу вот эта реализация, только там это поле почему-то называется «Search Categories» и выбирать можно только одну категорию. Попробуйте ввести туда «cat».
5. Выборку по тэгам делаем так же, как выборку по древовидным категориям, то есть «в этом тэге и подтэгах».
Плюсы системы: модератору не надо заранее изобретать всеобъемлющие категории, всё делают пользователи сами. Модератору достаточно один раз связать и причесать уже готовые, введенные пользователями, тэги.
Тестирование: Я взял 10000+ популярных тэгов с fotki.yandex.ru и попробовал их классифицировать, используя мою систему c nudnik.ru.
{kind=link}
Удалось разобрать 200 самых популярных тэгов, потом мне просто надоело. Самое главное, что мне не пришлось создавать ни одного нового тэга, пользователи действительно все сделали за меня, и все тэги уже имели привязанный к ним контент.
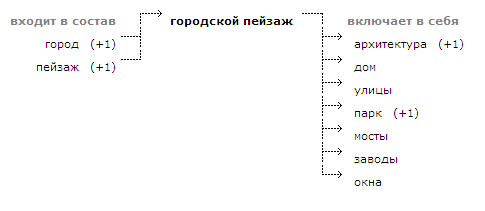
«Корневых» тэгов, из которых можно попасть в остальные, получилось всего 8 штук.
В качестве побочного эффекта сразу стало понятно, что интерфейс модерации можно сделать проще и удобней.
Итого: Для пользователей не меняется ничего (это важно), они все так же вводят тэги. Модераторы связывают тэги и указывают на ошибки («синонимы»). Эти ошибки больше не повторяются.
По выборке «животные» мы получаем всех животных, а не только тех, где пользователь соизволил указать «животные», а не конкретный их вид. Вместо страшного гиковского облака тэгов имеем более компактную и логически связанную псевдо-древоподобную навигацию.
Интерфейс.
Очень сильно хотелось написать прототип модераторского интерфейса и выложить в публичный доступ, но это было бы все то же «некое место, где все и каждый может составлять слова из букв», и ни к чему хорошему бы не привело.
Так что опишу словами.
Идеальный интерфейс для работы со словами — это... текстовый редактор. В нашем случае — поле ввода, типа textarea.
В несвязанном виде тэги имеют такой вид:
люди
я
дети
ню
природа
животные
домашние животные
кошки
кошечки
котенок
лошадь
Модератор берет и, натурально, работает с этим, как с текстовым файлом, используя простые правила, типа «знак „/“ является разделителем» и простые понятные механизмы, типа cut/paste.
После редактирования человеком текст выглядит примерно так:
люди / я
люди / дети
люди / ню
природа / животные
животные / домашние животные / кошки
кошки / котенок
животные / лошадь
кошечки
После нажатия на кнопку «ок» получаем уже связанные цепочки, отсортированные по алфавиту:
кошечки
люди / дети
люди / ню
люди / я
природа / животные / домашние животные / кошки / котенок
природа / животные / лошадь
Осталось придумать синтаксис для синонимов. Тут всё просто, главное слово — кошки:
кошки = кошечки = киски
Никто не мешает выводить синонимы в конце текста, понимать комментарии и прочие служебные символы. На выходе (в форме ввода) получаем текст, вида:
!люди / дети ## синонимы
кошки = кошечки = киски
## еще не имеют связи
динозавры## категории
!люди / ню
!люди / я
природа / животные / домашние животные / кошки / котенок
природа / животные / лошадь
Ну и мелочи — например, «!» в начале строки означает, что тэг действительно корневой (это вместо checkbox-а, ага), к тому же с сортировкой по алфавиту корневые тэги выводятся первыми. (Иногда надо связать несколько тэгов, но корневой тэг, который «достоин» попасть на морду сайта, например, выделить не получается).
Этот интерфейс в разы быстрей в работе, чем интерфейс с кнопочками, стрелочками и даже drag’n’drop-ами. Не говоря уже о поиске (Ctrl+F) и даже возможности банально впечатать нужное слово в нужном месте.
Стоимость разработки этого интерфейса стремится к нулю. Обработка данных тоже простая: режем на слова, сравниваем их с текущими тэгами, если есть «/» — проставляем связи.
Голосуй сердцем
Во всех голосованиях, типа +1/-1 должно быть на самом деле +N/-M, где N!=M (N не равно M).
Так как почти никто не понял моей гениальной гипотезы, поясню.
Но сначала — в чем смысл голосования вообще. Но это кто-то должен сказать все равно. Голосование — это выбор. Перед вами поставили пять президентов и под каждым повесили radiobutton. Выбери одного.
Понятно, что проголосовать одновременно за Жирика и за Зюгу нельза. А очень хочется.
Другое дело, когда у тебя есть много материала, и каждой твари можно проставить по паре оценку от 1 до 5. Конечная цель для голосования «на той стороне», то есть для сайта — всё тот же выбор, верней — отбор, отсеивание говна и составление более-менее адекватных топов.
Цель голосования для пользователя же совсем другая, ибо выбора нет. Пользователь может всем оцениваемым сущностям поставить 5 баллов. Полный аналог «я хочу, чтобы все были президентами одновременно». Понятно, что ценность этих голосов равна нулю, и в чистом виде такое почти не встречается, но возможность проголосовать так есть.
Ограниченного ресурса («выбери одного») нет, поэтому мотивов расходовать его экономно (или разумно) тоже нет. Но хоть какие-то мотивы нужны, поэтому и включаются эмоциональные механизмы, которые к тому же бинарны: «понравилось/не понравилось».
Разграничивать «понравилось, но не очень», то есть ставить «четверку» вместо «пятерки», смысла тоже нет: «вам что, жалко, что ли?». Нет, не жалко. Мы — добрые! А вот если нас, таких добрых, разозлить...
С точки зрения голосования, как выбора, дискретность шкалы имеет значение: чем больше шкала, тем выше точность. Наиболее подходящая шкала — стобалльная (при этом надо понимать, что голосование, типа 7.5 — это тоже стобалльная шкала, которая к тому же понятно для пользователя приводится в десятибалльной).
С точки зрения людей и особенно социально взаимодействия, наиболее удобна бинарная шкала: гавно/конфетка.
И 75-95% людей будут сводить любую шкалу к бинарной.
 Отсюда промежуточный вывод: как ты шкалу ни назовешь, ее все равно будут использовать ровно одним способом, как только поймут, что в ней «хорошо», а что – «плохо».
Отсюда промежуточный вывод: как ты шкалу ни назовешь, ее все равно будут использовать ровно одним способом, как только поймут, что в ней «хорошо», а что – «плохо».
Дискретная шкала просто имеет чуть больше смысла для 10% адекватных людей, которые будут использовать ее «идеологически верно». Еще один побочный эффект: чем больше делений у шкалы, тем больше шансов, что «щедрый» человек поставит 9.7/10 вместо 5/5: «это не так обидно».
Людей же, которые «голосуют сердцем», не пронять ничем, даже индивидуальной подписью к каждой оценке. У них все равно будет свой взгляд, «они так видят».
Налицо конфликт между авторами сайта и посетителями.
Наглядный пример: на картинке представлен результат разброса голосов на imdb.com по фильму «Крестный отец», который занимает первое место в top-250.

Видно, что 6% людей поставили фильму 1 из 10, то есть считают «Крестного отца» невероятным феерическим говном, после просмотра которого у них выпали глаза, случился самопроизвольный фимоз головного мозга и развилась патологическая боязнь кинематографа.
Очевидно, что это не так, даже чисто математически: далее график проседает аж до «семерки», и куда делись те люди, которые оценили фильм в промежутке от 1 до 7 — не понятно. Согласно математическим ожиданиям, их должно быть в разы больше.
Средний балл при этом у лучшего фильма всех времен и народов всего 8,7.
Конфликт «разруливается» элементарно: «one man, one vote» — принцип для наивных дураков, которого придерживаться не нужно.
То голосование, которое мы имеем на входе — это просто некие сырые статистические данные, которые нужно оценивать именно так — как данные. При этом вычисление среднего балла — наиболее нелепая вещь, которую можно сделать с этими данными. Средний балл не работает сразу (один проголосовавший), не работает и потом, потому что процент идиотов — величина постоянная, а бирки на них, увы, не развешены.
На imdb используется weighted vote averages:
IMDb publishes weighted vote averages rather than raw data averages. Various filters are applied to the raw data in order to eliminate and reduce attempts at ’vote stuffing’ by individuals more interested in changing the current rating of a movie than giving their true opinion of it.The exact methods we use will not be disclosed. This should ensure that the policy remains effective. The result is a more accurate vote average.
Простым языком это значит только одно: «не все голоса одинаково полезны».
Возвращаясь к «Во всех голосованиях, типа +1/-1 должно быть на самом деле +N/-M, где N!=M (N не равно M)» это значит только одно: «есть гипотеза, что люди „опускают“ с большей охотой, чем „поднимают“ (или наоборот), если эта гипотеза верна, то собранные статистические данные полезней считать не как тупую сумму, а с применением веса».
То есть, почти всё то же самое, что написано выше, но применительно к бинарной системе.
Проблема в том, что бинарную систему сложнее нормализировать. Совсем условно говоря, в стобалльной системе мы можем смело считать людей, поставивших «один», откровенными ретардами, в бинарной системе нам для этого просто недостаточно данных.
С другой стороны, «голосование», типа +1/-1 — практически идеальный инструмент для «опускания», поэтому использовать его нужно именно так: как массовое коллективное опускание. «Мне карму заминусовали». Еще один плюс такого голосования состоит в том, что влияние одного человека является понятной константой, и понятно, «как с этим бороться». В отличие от голосования по N-балльной шкале и подсчете среднего балла.
На skill.ru, кстати, я испробовал примерно четыре разных системы (с кучей вариаций), в конце концов пришел к формулам, согласно которой помимо всего прочего голоса некоторых людей в крайних случаях вообще не учитываются, причем на основе их всех предыдущих голосов. То, что вес каждого голоса учитывается индивидуально — тоже очевидно. Причем ручного «бана» там нет, все подчиняются одним и тем же математическим правилам. Теперь топы, по крайней мере, можно смотреть без содрагания.
(Не знаю, почему до сих пор никто не реализовал «спарринговую» систему голосования: пользователю дается три-пять случайных работ, но примерно одинаковых по рейтингу работ, а он должен выбрать одну).
Таким образом, идеальная система голосования:
1. Предлагает не бинарную шкалу, главным образом для себя, но еще и для маленького процента нормальных людей.
(Пользователи говорят, что им «привычна» пятибалльная, но они просто врут, ее просто проще привезти к бинарной. На «серьезных» проектах я бы делал 100 балльную и приводил всё к виду 7.5/10).
2. Не навязывает пользователям трактовку этой шкалы (!).
3. Не обязана и не должна учитывать каждый голос одинаково.
4. Имеет закрытые механизмы подсчета конечного рейтинга.
PS.
Самое главное, о чем забыл написать подробно — подумал, что это и так очевидно: для чего нужно голосование, и что оно меряет.
Голосование меряет только человеческий интерес. И всё. Те, кто думают, что голосованием можно измерять качество — в лучшем случае заблуждаются. Если будет анонимно голосовать одна и та же группа экспертов по всем работам, при этом никак с этими работами не связанная, — тогда может быть.
Голосование измеряет популярность.
В этом плане десять «четверок» гораздо ценней, чем одна «пятерка», да и вообще, количество оценок — тоже релевантный фактор.
Польза для сайта от голосования абсолютно та же: предлагать на выходе список чего-то, что может понравиться среднестатистическому посетителю.
То есть всякие артхаус и прочее geekery — это не показательный пример вообще. Другое дело, что на основе все того же голосования можно сделать фичу, типа «люди, которые поставили этому фильму „пять“, так же поставили „пять“ следующим фильмам», — тогда это будет работать даже на примере артхауса.
Принцип, кстати, всё тот же: пользователю на входе дается N-балльная шкала, всё остальное — просто работа с данными.