Гипертекст — идея хорошая. Прочитать про нее можно (и нужно) в моем дипломе. Но конкретно так называемый «веб» и html — предельно кривая ее реализация.
Вот только некоторые «родовые травмы»:
1. Односторонние ссылки.
Абсолютный и полный бред. Если я связываю документ А с документом Б, то велика вероятность, что документ Б тоже как-то связан с документом А. Ну, если подумать, да?
Средствами же «веба» владелец документа Б никак не знает, что на него стоит ссылка из документа А. Рефереры — это, увы, совсем не то. Думаю, не надо объяснять, почему. Trackback — кривая заплатка на эту тему, которая не работает по понятным причинам: можно «подделать» и использовать для спама.
2. Невозможность сослаться на часть документа.
Якоря не считаются — автор должен их предварительно расставить. При этом его расстановка якорей может не совпадать с вашим представлением и нуждами. Я не могу взять и произвольно сослаться, допустим, на абзац из текста Б. Хотя деление на абзацы есть.
Так что минимальная и единственная единица гипертекста — это один документ, то есть один URL и все, что по этому URL-у находится. В Библии и то круче сделано. Понятно, что таких единиц должно быть минимум три, условно – «папка, документ, абзац».
Грубо говоря, тупо на уровне разметки должна быть возможность сослаться на любой абзац, не говоря уже о заголовках, в идеале — на конкретное слово.
3. Не использование децентрализации системы.
Децентрализация является одной из главных особенностей интернета. В какой-нибудь p2p системе, если один и тот же файл находится у кучи пользователей — это все равно один файл, его система однозначно идентифицирует, как уникальную сущность. Это также решает в какой-то мере проблему битых ссылок.
В интернете я же скопировал страницу, разместил по новому адресу — и опа, новый документ, связь с оригинальным документом и не установить.
Этот пункт вообще-то самый сложный. Если бы «весь интернет» находился «на одном сервере», то можно было бы отслеживать и перепечатки, и ссылаться на части документа, и прочее, и прочее. Интернет, однако, «у каждого свой». Да и вообще, в целом — совершенно дикий.
Что забавно — поисковики берут на себя функцию этакого «супервизора»: стараются сначала выдавать предположительно оригинальные источники, а не перепечатки, в какой-то мере поддерживают целостность («посмотреть страницу в кэше»), стараются ранжировать информацию по «значимости».
Тот же индекс цитирования — это попытка понять «крутизну» документа по количеству ссылок на него, но этот функционал должен быть «встроен» в реализацию гипертекста и сопутствующий софт.
Кто виноват.
Виноваты все. Даже мы с тобой.
С одной стороны — создатели языка HTML, которые допустили такой дизайн, при котором язык семантической разметки мог быть использован, как язык визуальной разметки. Идеальный же дизайн не допускает использование предмета не по назначению.
В результате вся история языка — борьба за отделение отображения (div, css) от смысловой разметки и полное отсутствие развития смысловой разметки.
Конкретные примеры я уже приводил — невозможность сослаться на часть документа, невозможность делать банальные сноски, то есть «ветвить» документ.
Максимум, что можно сделать – поставить якорь внутри документа на сноску и обратно. Или что-то в духе того, как я сделал в дипломе.
Но надо отдавать себе отчет в том, что это тоже — заплатка, и каждая сноска является независимым документом, никак не связанным с основным. Наглядный пример — к чему эта сноска? Обратной-то ссылки нет, ага.
С другой стороны — виноваты и производители сопутствующего софта, то есть браузеров, движков сайтов и даже html-редакторов.
Нюанс заключается в том, что первый браузер, первый html-редактор, сам html и протокол http придумал один человек. До есть это всё — одна система, и рассматриваться должен не просто html, а всё, как единое целое.
Основная проблема еще и в том, что в идеале гипертекст не только читается нелинейно, но и пишется нелинейно. Инструментов для этого практически нет. Да и всяких полезных штук в языке на этот случай — тоже.
А если есть, то браузеры просто на них «забили».
Например, я могу любому элементу присвоить атрибут title. Это будет практически сноска или комментарий. Более того, браузеры даже отобразят этот title, потому что должны по стандарту. Но, естественно, заранее о том, что тут есть title, они вас не предупредят. Поддержка для галочки.
Поэтому приходится использовать самодельные заплатки и как-то самому выделять наличие title-а.
Вообще же надо «пинать» не только html, но и всё в целом. Браузер по определению (browser) — средство навигации. Сейчас из навигации в браузерах есть только кнопки «вперед-назад», а крутизна браузера зависит от того, как хорошо он рендерит страницы.
Например, вещи, типа link rel="next" понимают не все браузеры, хотя, если вдуматься, навигация, которая не является смысловой частью документа, обрабатываться должна именно так. Грубо говоря, меню навигации по сайту относится к сайту, а не к телу (body) html-документа, в котором оно размещено.
Иными словами, чтобы писать «полноценный» гипертекст средствами html и отображать его современными браузерами, приходится приспосабливаться. Даже в пределах одной html-страницы.
Про взаимодействие между разными сайтами я вообще молчу.
Что делать.
Наиболее близка к духу гипертекста википедия. Но главным образом потому, что там как раз всё находится в одном месте. Маленький гипертекстовый рай, сделанный своими руками. Еще один пример — только не смейтесь — формат chm. Только потому, что позволяет нормально объединять несколько документов.
Что делать — понятно: раз на html уже не повлиять, остается только писать собственный «окологипертекстовый» софт так, чтобы не было мучительно больно.
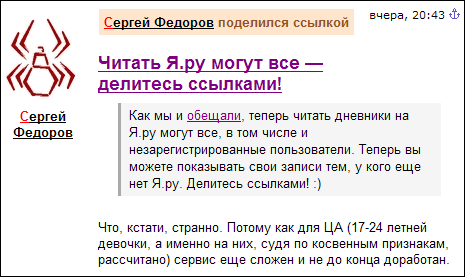
Например, в ярушечке, при всей его ориентации на леммингов, есть неплохие вещи: встроенная возможность дать ссылку на чужой пост и процитировать его целиком, при этом чужой пост не «копипастится» в ваш, а воспроизводится из источника. То есть это — действительно ссылка, которая просто «разворачивается» софтом:
Эта заметка не оплачена из кармана Яндекса.